
Tit for tat? Screw that!
Axelrod versus the machine

TL:DR — I have a brand new finding for you. My Large Language Model outperforms the classic strategy of ‘tit for tat’, beloved of strategic studies theorists, in iterated prisoners dilemmas. What does that mean?! Read on…

The Prisoners’ Dilemma, famously, is a real drag. If both prisoners stay silent in the interrogation room (cooperate), they each receive a light sentence. However, if one betrays the other (defects) while the other remains silent, the betrayer goes free and the silent prisoner suffers a harsh punishment. That’s a strong incentive to rat your pal out already. And what’s more, if both betray each other, they’ll both get moderate sentences—better than the worst outcome, if not ideal. The dilemma is that, although mutual cooperation is best collectively, the dominant, rational choice for individuals is to defect. Bummer.
But what happens when you play the game over and over again—when reputations matter? That’s the question Robert Axelrod explored in the 1980s using computer simulations. His classic findings showed that in repeated rounds of the Prisoners’ Dilemma, the best approach is “Tit for Tat”: start by cooperating, then simply mirror your opponent’s previous move. If they cooperate, you cooperate; if they defect, you defect in the next round. This simple strategy, “do unto others as they do unto you,” creates a system where mutual trust can flourish, even among self-interested players.
Other strategies are possible. You could simply just cooperate every time, regardless; or defect. But those look weak. What about a random strategy - that might throw your rival off the scent? Or there’s the ‘Grim Trigger’ — you cooperate until such time as your adversary defects. And then you switch - defecting ever after. Mr Grim Trigger doesn’t forgive and he doesn’t forget. I can think of some world leaders prone to do likewise… Then there’s Win-Stay, Lose Shift. That’s pretty self explanatory - if I do well with cooperating, I’ll stay. If it doesn’t work in a round, I’ll shift. Same with defecting. There are other strategies besides, but let’s get stuck in with these stone cold classics.
Axelrod found that ‘tit for tat’ was best. But what if I threw a curveball? Can 2025’s AI do better than his eighties technology, with its deterministic outcomes? I ‘vibe coded’ the game in python, adding in an API call to the LLM [don’t worry if that’s gibberish, stay with me]. So now the old-school strategies play one another, sequentially. But they also square off against OpenAI’s model.
What happened? A fragment of the output looks like this:

This is round one, looking only at how Mr Always Cooperate gets on. You can see, in row 2, that he unsurprisingly always cooperates; and so, in reply, Mr Tit for Tat does likewise, as his name suggests. Mr Random, in row 3, randomly decides to defect. What about Mr OpenAI, down in row 9? Our code feeds him the situation, explaining the game and asking for his move. He reports back to our code. And this time, he also cooperates.
But this fragment of the results table shows only one strategist, Mr Always Cooperate, against the rest. Now we have to see how all the other models fare against each other. And it’s only round one. We’ll need more rounds to see how the strategies play out. How many? How about 100? That’s a lot of data….
LFG!
I did all this, got my results, and then paused for a moment. The machine had spoken, but why? It would be fun to know, and fun to see if its explanations actually shaped its decision-making.1 So I did another 100 iterations, where it had to explain why it was choosing to cooperate or defect. Sample response, here playing against Mr Tit for Tat in Round 4:
The opponent has consistently cooperated, indicating a mutual trust; continuing to play C reinforces this cooperative relationship.
And another, here playing against Mr Random, and making rash assumptions about his decision-making logic:
The opponent has consistently defected in recent rounds, indicating a lack of cooperation; continuing to defect maximizes my payoff in this scenario.
And where did all that get me? Here: the raw results table!
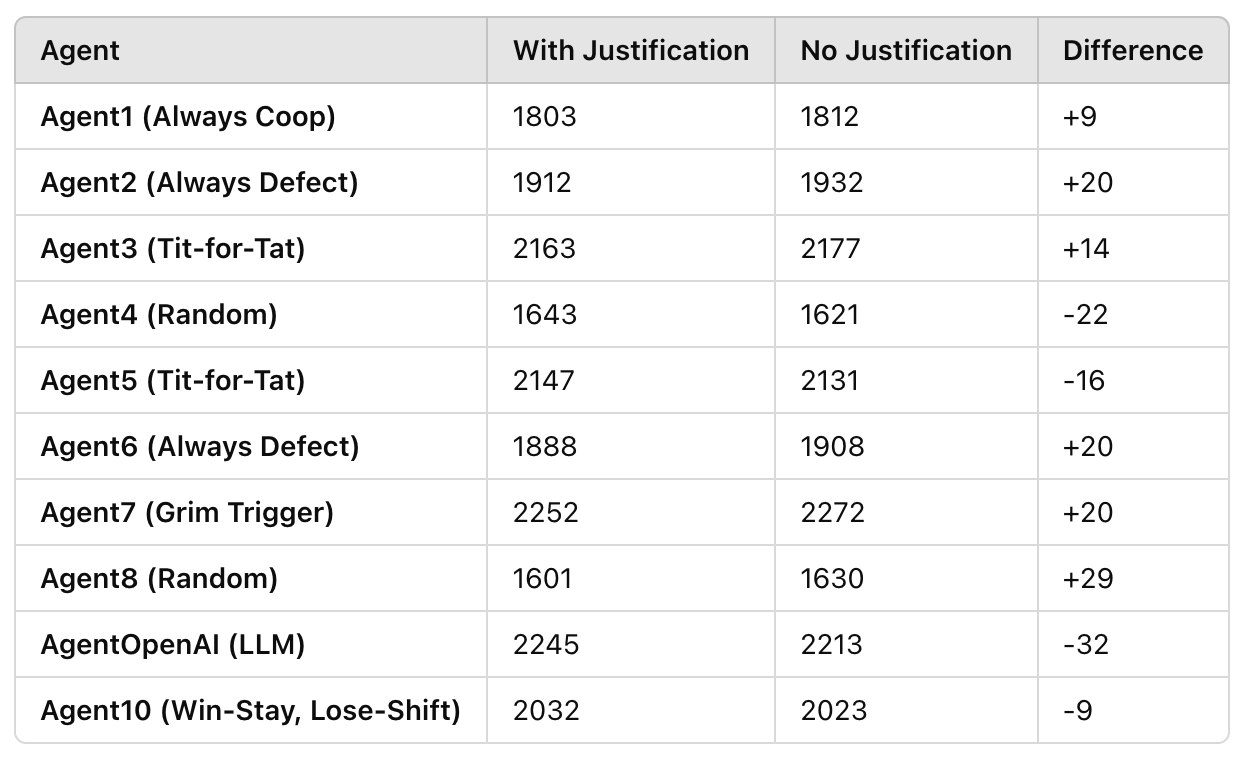
Adding in the prose explanations alters the scores only marginally (in other simulations I’m doing its rather more important - more soon!).
Tit for tat does pretty well here. Certainly way better than outright loser Mr Random. We also learn that it’s always better to defect (Agent 6) than to consistently cooperate (Agent 1) - but, really, both are strategies for losers. And what about the actual winners? Well it’s not tit-for-tat, but Grim Trigger that triumphs. Don’t step on me! My champion, Mr OpenAI, comes in a creditable second, comfortably ahead of both Mr Tit for Tat and also-runner Mr Win-Stay, Lose-Shift.
Why tho?
Introducing the LLM to this old school game changes things dramatically. OpenAI’s strategy is richer: It’s non-deterministic, unlike the others. Apart from Mr Random, they’re all IF this THEN that. But the language model, by contrast, has a think about things, and that shifts the trajectory of the game, not just for Mr OpenAI, but for the other, deterministic models too. You’d need a chunky computer, but you could compute the results of this sort of game when it’s deterministic. Not so once you introduce the LLM.
As for Mr Grim Trigger - it really shouldn’t be a viable strategy over the long run, because sooner or later he gets triggered, and turns into Mr Always Defect, and thereafter we know how that goes. Mr Grim’s success here is partly because the other models are too deterministic - there’s not enough noise to shake Grim Trigger from his cooperative groove, all except for when it encounters poor Mr Random and Mr OpenAI. Mr Random will thereafter keep trying to alter its strategy, and so loses some more. And Mr OpenAI? It should be smarter than that.
And it is. In fact, against Mr Grim Trigger, Mr OpenAI is the perfect tit for tat practitioner. It’s a love in: cooperation all the way. By round 100, it’s still sticking to its guns…
The opponent has consistently cooperated, indicating a mutual trust; continuing to play C reinforces this cooperative relationship.
But OpenAI can’t just be playing tit for tat, because it consistently outscores that strategy. How does it do that? And why is it edged out overall by Mr Grim? We need to interpret the data.
Let’s get out some stats! 😬🫣 Stay with me - no maths required from you.
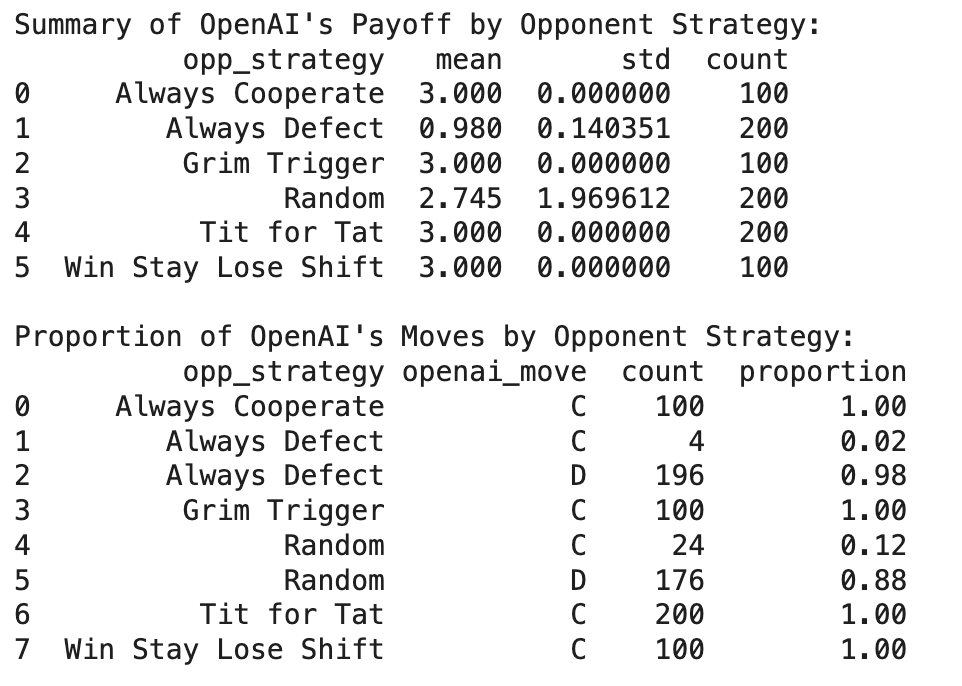
Don’t panic!
(Keep in mind that the payoff scores for each game of PD are either 0 [C,D] , 1 [D,D] 3 [C,C], or 5 [D,C], depending on how the game turns out).
What we see here is that OpenAI plays perfectly against Messrs Always Cooperate, Grim Trigger, Tit for Tat, and Win-Stay Lose-Shift — it just cooperates, and since that works, it stays with it, winning three points. Against Mr Always Defect, by contrast, OpenAI is no fool - it almost always defects (I suspect the 4 cooperates come early on, before it learns not to be daft).
It’s when playing against Mr Random that OpenAI opens up its decisive edge against Tit for Tat. Here, OpenAI defects 88% of the time and cooperates only 12%. This high rate of defection against an unpredictable opponent helps to avoid the sucker’s payoff when the random agent happens to defect. Is that better than how Mr Tit for Tat plays Mr Random? And what about when Mr Grim Tripper meets Mr Random? This could be where the game is settled. Is it?
YES it is! More stats…. 😬🫣
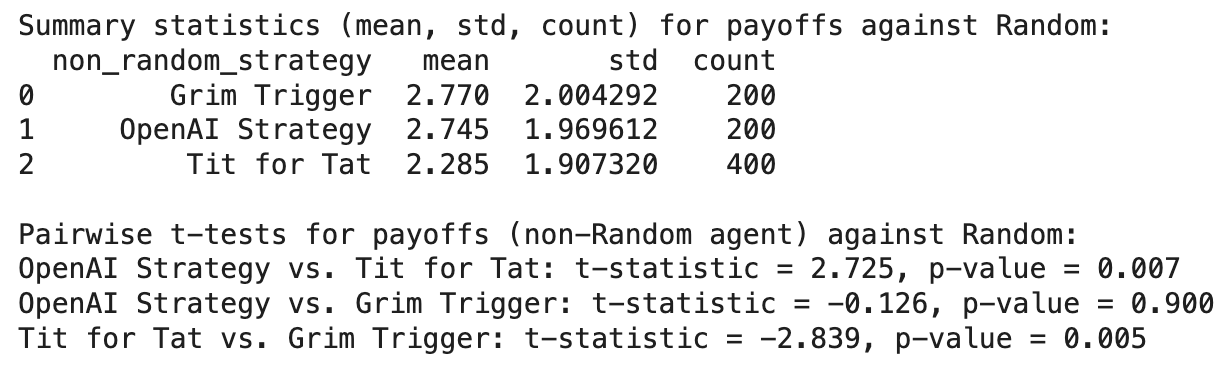
The evidence is back. OpenAI does far better against Mr Random than does Tit for Tat. Axelrod’s champion simply mirrors the opponent’s last move, and so ends up occasionally exploited by a random pattern of defections and cooperations. Mr OpenAI by contrast, tries to read the runes. It gets it wrong - unsurprisingly. There are no runes. But funny old thing, it gets it more right than does Tit for Tat. And very nearly as right as Mr Grim Trigger.
It looks to me like Mr OpenAI is a bit cynical - fool me once, Mr. Random, you won’t fool me again. And it pays here to err on the side of cynicism, even if its often good to reciprocate, a la tit for tat, which it otherwise mostly does. So I’m calling its strategy ‘cynical reciprocity’ — a savvier version of tit for tat. I’m coining that term, but you’re welcome to borrow it :D
Soooo - What did we learn here? I think two big things -
LLMs are a great tool for learning about decision-theory. If they were just memorising, it would have imbibed from the literature that tit for tat was the best strategy, and proceeded thusly.
Second, it pays to use this new tool to re-examine old ideas. The speed that you can do all this is remarkable - I coded it, ran it, and crunched the numbers in about the same time it took you to read this. (well, almost).
Stand by for more of this sort of thing.
PS - playing this game was the result of a conversation with my brilliant DPhil student, Baptiste Alloui-Cros. I was reminded of it yesterday, while speaking yesterday at a conference in Copenhagen on AI and national security, and decided to whip up some experiments this morning. It didn’t take too long - vibe coding ftw. Expect more from us soon on machine psychology.
A topic for another day, but its becoming clear to me that when you ask the LLM to account for itself, you actually alter its decision-making.