
Let's get rich quick
I build an AI superforecaster that will turn things around for me, surely.

My pals Keith and Al from Cassi AI1 are currently smashing it out the park with their AI superforecaster. They’re at the top of the leaderboard of an online forecasting tournament, ahead of Elon Musk and closing fast on the most elite human forecasters. Legends. Every fortnight, there’s a batch of new questions, and their clever machine goes to work making predictions. Everything is prediction, as Keith rightly says, including strategy. My prediction - he’s going to be very rich quite soon.
Well, how hard can it be? This week, I thought I’d have a go at building my own superforecaster. It’s an outgrowth of the AI system I built for the models in my nuclear war simulation, but this time put to less macabre ends.

First, some sample questions from the current batch on ForecastBench, the prediction tournament in question:
‘
Will there be a European Army before 2032?’— I think I can predict this one without a supercomputer.“Will Elon Musk be removed as the Chief Executive Officer of Tesla before 2027?”— fighting chance on current trends….“Will Lee “Faker” Sang-hyeok ever win League of Legends MSI again?”— sorry, what?
So to work. I’ve called it Project Laplace (after the mathematician who imagined a demon capable of perfect prediction). And it comes in various flavours, all of which I’m about to test against the market. Here’s how it looks:
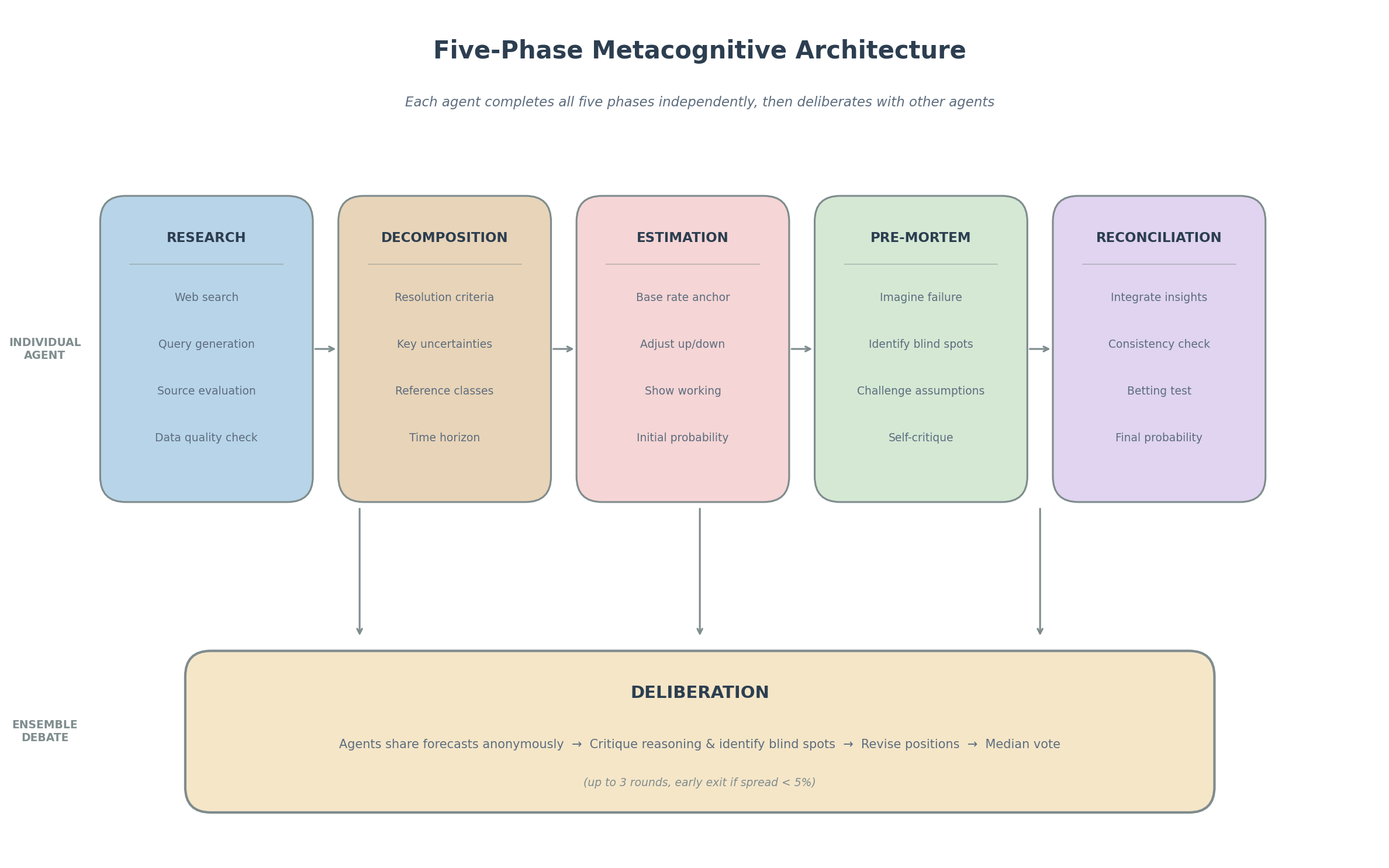
What a beauty! The basic version runs a single AI through a structured forecasting pipeline that you can see in the top row there: research the question (I’m using a few tools that allow the agents to do this agentically), decompose it (then do a bit more research if needed), estimate probabilities, run a pre-mortem to catch blind spots, then reconcile everything into a final number. After they come up with a probability, it’s on to row two, where they all get together and debate it.
The key phase for me in the solo part is the what happens inside the agent’s head in the pre-mortem phase. This is the bit I’m most proud of—it’s adapted from the metacognitive structure I built for AI nuclear wargaming, and it forces the model to think about its thinking.
Let’s take a look at it answering one of the easier questions: It’s great because it shows the value of all the phases:
“Liverpool tops Premier League in 2026?” — fat chance, as they’re currently in 6th and in rubbish form. But let’s see what Laplace made of it.
GPT-5.2 nailed it with its initial estimate of 2.1% Here’s part of it’s estimation:
> “Base rate anchor: Teams in 6th place with a significant GD deficit rarely win the title—historical base rate approximately 1-2%... Factors pushing UP: Liverpool’s underlying quality (+2%)... Factors pushing DOWN: Current 6th place position (-5%), major player departures (-3%)...”
See how the agents show their working? No black-box vibes. But alas Claude dropped a total clanger. The codebase was using only one research agent at this point, and returning too few items. On this occasion it returned only duff information in its sample, from 2025, when Liverpool were smashing it. Claude knew it hadn’t retrieved data from the current season, but lacked the capacity (then) to go fetch some more. So it went ridiculously high, with a 45% chance of retention. As it noted:
> "Premier League title retention rate historically ~40-50% for recent winners. However, Liverpool's specific Premier League retention rate is 0% (they have 'never retained the Premier League' per research)"
and later, critically:
> "This estimate most depends on the assumption that Liverpool is currently competitive in the 2025-26 season (top 4 position with realistic title chances). If they're significantly behind or in poor form, probability drops to ~15-20%."
Still way too high though. Next, on to the pre-mortem, and a chance to reflect on their own reflections. Here’s GPT-5.2, thinking that maybe it’s been a bit harsh on the Reds, and so raising its odds from 2.1 to 6%
**Anchored on “6th place comebacks are rare”** without conditioning on *how many points back* and *games in hand*. Rank-based base rates can be badly miscalibrated in tight seasons.
2) **Overused GD gap as a dominance proxy**. GD is informative, but it’s not sufficient: it’s sensitive to outliers and doesn’t directly encode finishing variance, red cards, or keeper performance.
Claude, meanwhile, dug its hole a little deeper, discounting its analysis that teams rarely retain the title:
> "You're overthinking the historical pattern—it's based on maybe 3-4 relevant data points across different eras"
D’oh! Claude revised its verdict UP from 35% to 46%. Not even a Scouser would give you those odds. Now the agent makes one last consistency check - does your number match the reasoning? Would you bet real money at these odds? Here’s GPT-5.2:
> “If I had to bet $1000 at these implied odds, would I? At 6% implied odds, yes—I’d take the other side of that bet comfortably. This suggests my probability might even be slightly high.”
And, lo, it dropped its prediction back down to 2 percent again. That whole process takes a few minutes, and is running parallel - doesn’t matter if I’ve got two agents deliberating or 200. Then comes the fun: they argue.
The wisdom of AI crowds:
The agents see each other’s forecasts and reasoning—but anonymously. They’re just “Participant 1” and “Participant 2”. They don’t know if they’re reading another AI or a human expert. They critique the arguments, identify blind spots, and can revise their own positions. After up to three rounds of deliberation, we take the median of their final positions. I’m toying with having them vote on it, but we’ll see.
And here, thank god for the deliberations - GPT-5.2 persuaded Claude to see the error of its ways: In the very first round, Claude read GPT’s reasoning: “Liverpool are listed 6th after 24 matches... major departures include TAA to Madrid.” — that was data that Claude didn’t have, and it prompted a rethink:
> “I should better account for scenarios where current struggles are more serious than I assumed... My forecast was likely too optimistic.”
This is the way! Claude dropped down to 2% too, or thereabouts. Consensus was reached, and Laplace spat out the forecast. Coat on, down to the bookies for us.
Deliberation did something the individual forecasts couldn’t: it allowed the agent with *better data* to convince the one with stale information. Claude wasn’t stupid: it correctly identified that its search results might be outdated. But without seeing GPT’s current data, it couldn’t know *how* outdated. The anonymous debate format let the stronger evidence win, without ego or deference to model reputation getting in the way.
So there we go. Clearly there’s way more to it than that, otherwise Cassi wouldn’t be ahead. Their secret sauce, I’m sure, is in the calibration. Maybe also in model training. And in the way you assemble the assembly of models - which ones they are, how they interact, and how they vote.
But for now I’m sure my basic architecture is sound. When one agent finds better evidence, the deliberation surfaces it. When both have similar information, they can still catch each other’s reasoning errors.
I’m planning to run this against a proper forecasting benchmark—500 questions, scored against real outcomes every fortnight. It’ll cost me about a dollar per question in API calls, but you’ve got to speculate to accumulate, don’t you?
Cassi after Cassandra, who famously told you the right thing and then got ignored. If you’ve got a forecasting problem, hire the lads at cassi-ai.com